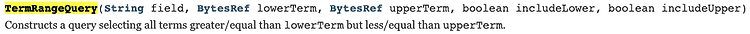[Lucene] 루씬 - 검색 #2 - Query의 종류 이번에는 Query의 종류에 대해서 설명합니다.검색을 하다보면 단순히 "people" 같은 문구 한개를 찾기 보다는, 여러 조건을 조합해서 질의를 만들어야 할때가 있습니다.따라서 lucene에서는 기본적으로 사용하는 Term query 이외에도 다른 query들을 지원합니다.이런 쿼리들은 org.apache.lucene.search.query 패키지 안에 존재합니다. lucene api는 8.2.0을 기준으로 합니다.또한 예제는 Kotlin으로 작성되었습니다. Term query앞의 예제에서 계속 사용한 query 입니다. 검색 할 Term을 설정하여 해당 Filed에서 요청한 문자를 찾습니다.이건 앞쪽에서 계속 사용해 왔으니 예제는 생략합니다.검색할 문자에 띄어쓰기가 들어있다면 TermQuery를 직접.. 개발이야기/Lucene & Solr 5년 전
[Lucene] 루씬 - 검색 #1- IndexReader, IndexSearcher 앞서서는 루씬의 index에 관련해서 알아봤습니다.물론 앞선 예제에서 따라하기 형태의 index, search를 전부 경험해볼수 있으니, 기본적인 사용법은 예제와 같습니다.(기본 따라하기 예제 - https://tourspace.tistory.com/237) 루씬에서 지원하는 검색은 질의(Query)와 문서간의 유사성을 판단합니다.여기서 유사성은 Document에 질의한 term이 나오는 횟수로 결정되면 이 유사도로 scoring을 하고 해당 문서를 결과로 return 합니다. 검색 indexing처럼 크게 API 어렵거나 사용이 복잡하지 않습니다.다만 검색에서 기본적으로 사용되는 class들에 대해서 간단하게 정리하고자 합니다.이 글은 lucene v8.2.0 기준으로 작성되었습니다. 모든 예제코드는 .. 개발이야기/Lucene & Solr 5년 전
[Lucene] 루씬 indexing #1 - 기본 루씬의 기본 동작은 indexing과 searching 입니다.word든 xml이든, txt이든 csv든 간에 먼저 text로 만든 다음에 이를 검색하기 좋도록 index를 만들고 이를 이용하여 검색을 진행합니다. Inverted IndexingLucene은 빠른 전문 검색(Full Text Serach)를 하기 위하여 inverted index를 생성하여 사용합니다.Lucene 관련 공식문서나, 기타 문서들을 찾아보면 inverted index라는 용어를 많이 사용하는데, 말 그대로 일반적인 index의 key와 value를 뒤집어 놓은 형태입니다. 말보단..사진이 빠릅니다. 먼저 책상의 개발서적중 아무거나 하나를 꺼냅니다.(저는 최근 가장 재밌게본 "다시 미분적분"의 책을 꺼내서 사진을 찍었습니다)그.. 개발이야기/Lucene & Solr 6년 전
[Lucene] 루씬 - Document Field types Document를 생성할때, 각각의 field를 type에 맞게 결정해 줍니다.Value의 저장여부 부터 term vector 생성여부, data type에 따른 field등 각가 다르게 설정하기 때문에 Document가 어떤 Field를 지원하는지에 대한 내용을 정리합니다.이 문서는 apache 공식 API 문서를 참고하였습니다.http://lucene.apache.org/core/8_2_0/core/index.html Lucene version 8.2.0 StringFieldindex에는 포함가능하지만 tokenize는 하지 않습니다. 따라서 string 전체가 하나의 token이 됩니다.사용 예시: "국가명" 또는 "id" 값등 생성자의 인자중 value로 String을 넣으면 textual Str.. 개발이야기/Lucene & Solr 6년 전