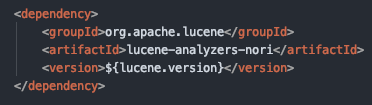
[Lucene] 루씬 indexing #5 - N-Gram, 한글 Analyzer (3/3) 영어와 같이 단어가 공백단위로 분리된다면야 tokenizing 하기가 쉽겠지만 제가 아는 아시아 언어들은 띄어쓰기만으로 tokenize를 하면 제대로 term을 만들기 쉽지 않습니다.물로 영어도 단어의 원형, 동사의 원형으로 변환하는 과정을 거쳐야 하겠지만, 한글이나, 일어(일어는 띄어쓰기가 없는걸로 알고 있습니다만..)등의 언어는 공백으로 분리해서 만들어진 term으로는 검색효율이 떨어집니다."사과와 포도는 참 달다"를 "사과와" "포도는" "참" "달다" 분리했을때 "사과"로 검색하면 검색결과가 0이겠죠~N-Gram 분석기는 글자를 한글자씩 연결해 가면서 term을 생성하는 방법을 말합니다. 이 글은 lucene v8.2.0 기준으로 작성되었습니다. 모든 예제코드는 Kotlin으로 작성되었습니다. N.. 개발이야기/Lucene & Solr 5년 전
[Lucene] 루씬 Indexing #3 - Analyzer 기초 (1/3) 루씬에서 Indexing 작업은 주어진 Text를 Term으로 쪼개서 검색 가능한 최소한의 단위로 만드는 작업이라고 볼수 있습니다.그리고, 그 단어들을 검색하기 편하도록 거꾸로 정리 놓는거죠. (Inverted index 말입니다.) 이번에는 indexing 작업중에 Text를 쪼개서 Term으로 만드는 방법에 대해서 설명합니다.이렇게 대상 Text를 잘게 잘라서 term을 만드는 작업은 Analyzer가 수행합니다. 이 글은 "실전비급 아파치 루씬 7"을 참고하였습니다.자세한 설명 및 다양한 예제는 해당 책을 구매하여 확인하시기 바랍니다. ※ 모든 예제 코드는 Kotlin으로 작성되었습니다. (Lucene library 원본 코드 제외) 크게 나누어 분석은 아래의 단계를 거칩니다.CharFilter -.. 개발이야기/Lucene & Solr 6년 전