[Lucene] 루씬 - Document Field types
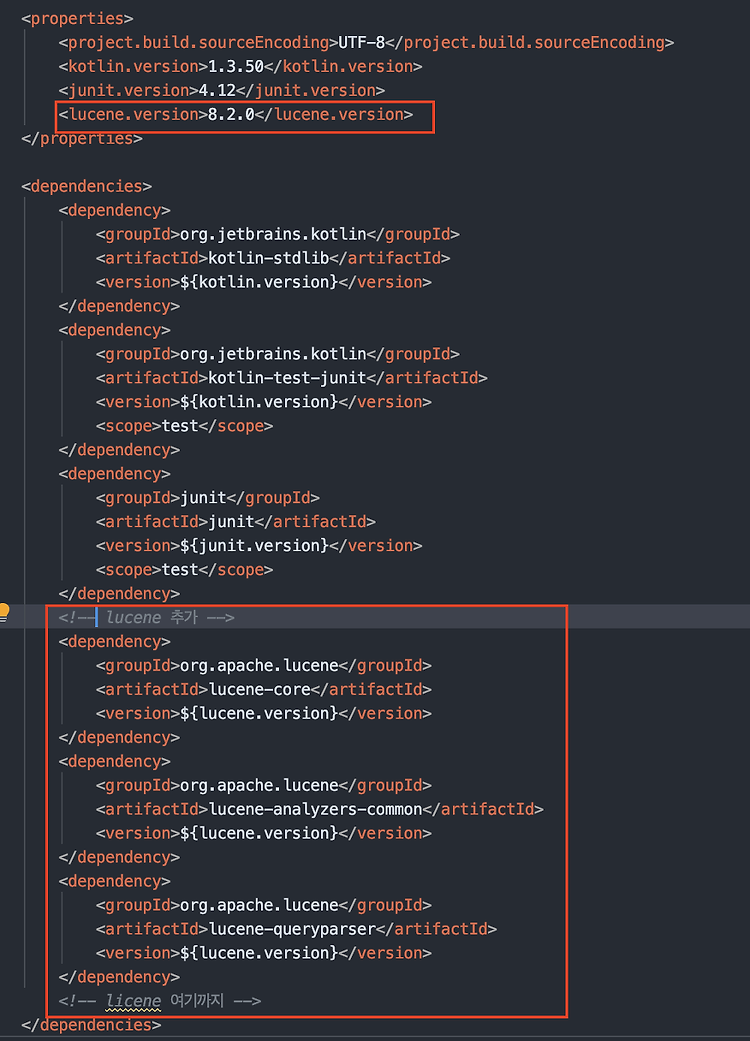
Document를 생성할때, 각각의 field를 type에 맞게 결정해 줍니다.Value의 저장여부 부터 term vector 생성여부, data type에 따른 field등 각가 다르게 설정하기 때문에 Document가 어떤 Field를 지원하는지에 대한 내용을 정리합니다.이 문서는 apache 공식 API 문서를 참고하였습니다.http://lucene.apache.org/core/8_2_0/core/index.html Lucene version 8.2.0 StringFieldindex에는 포함가능하지만 tokenize는 하지 않습니다. 따라서 string 전체가 하나의 token이 됩니다.사용 예시: "국가명" 또는 "id" 값등 생성자의 인자중 value로 String을 넣으면 textual Str..