
앞서 csv.DicReader를 통해서 Dictionary 형태로 데이터를 로드했습니다만 pandas를 이용하면 엑셀의 2차원 배열을 그대로 data frame으로 가져와서 사용할수 있습니다. 마치 DB의 테이블처럼 말이죠.[1]
먼저 pandas를 이용하여 excel을 로드하는 기본적인 구문부터 보도록 하겠습니다.
이글은 Phtyon 3를 기반으로 작성되었습니다.
pandas import 및 데이터 로드
import pandas as pd
xls = pd.ExcelFile('yelp.xlsx')
df = xls.parse('yelp_data') # yelp_data sheet를 읽는다.
df2 = xls.parse('cities') # cities sheet를 읽는다.
print(type(df))yelp.xlsx라는 엑셀파일을 pd.ExcelFile()로 읽었습니다.
이렇게 읽어온 이후 parse()를 통해 특정 sheet의 내용을 가져올 수있습니다. 예제에서는 yelp_data, cities 두개의 sheet의 데이터를 읽어 dataframe에 담았습니다. 마지막 print문의 실행값은 아래와 같습니다.

단 두줄로 excel의 데이터를 담아 왔네요.
사용할 데이터 예시
먼저 불러올 excel의 구성은 아래와 같습니다.

엑셀파일에는 세개의 sheet가 존재하면 나머지 두개는 아래와 같습니다.


이 데이터의 특징으로는 가장 기본이 되는 "yelp_data" sheet에 각각 다른 sheet의 id값을 물고 있는걸 알수 있습니다. DB의 join을 위한 key 같네요.
Dataframe의 정보보기
먼저 data frame의 기본적인 정보를 표시해 보겠습니다.
# describe() - 전체 내용 요약
df.describe() # df의 정보 보기describe() 함수를 호출하면 아래와 같이 컬럼당 총 row개수와 평균, 표준편차등의 정리된 표를 한번에 볼수 있습니다.

가지고 있는 데이터가 600개짜리임을 알수 있습니다.
# shape - size 반환
print(len(df)) # count 세기
print(df.shape) #(row수, column수) size 측정len() 함수 이용시 단순히 row의 개수를 반환하지만 shape의 경우 가로x세로 = row x column의 개수를 tuple로 반환해 줍니다.

# count() - 컬럼별 개수 반환
print(df.count()) # 컬럼별 row 개수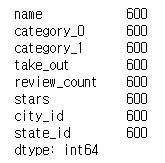
각 컬럼이 가지는 row 개수를 반환합니다. 여기는 전부 데이터가 채워져 있는상태이므로 전부 600개라고 반환 됩니다.
# columns - 컬럼 이름 반환
df.columns ## 컬럼만 표시
print(df.columns)
print(type(df.columns))결과는 아래와 같습니다.

# dtypes - 컬럼별 데이터 타입 표시
print(df.dtypes) # 컬럼별 데이터 타임 표시
각 컬럼의 데이터 타입을 나타냅니다. 나중에 casting 하려면 dtypes를 이용한 선 확인이 필요하겠죠?
Data의 출력
#head() - 상위에서 특정 개수만큼 보기
데이터가 방대하다면 print로 다 찍어보기는 어렵습니다. 상단에 위치하는 데이터를 제한해서 보려면 head()함수를 이용합니다. 기본값은 5개 이며, 그 이외의 값은 직접 지정할 수 있습니다.
print(df.head()) # 기본 상위 다섯개만 보기
print(df.head(100)) #100개까지만 보기
컬럼이 여러개라 한줄에 표현하지 못했지만 head() 호출시 5개, head(100) 지정시 100개를 반환함을 알 수 있습니다.
#drop_duplicates() - 중복제거
중복된 컬럼을 제거합니다. 단 제가사용한 데이터에서는 중복된값이 없어 그대로 출력되기 때문에 결과는 표시하지 않았습니다.
df = df.drop_duplicates() # 중복제거#[COLUMNS] - 특정 컬럼만 보기
아래와 같이 [] 안에 특정 컬럼명이나 컬럼명을 갖는 list를 넣으면 해당 컬럼만 출력할 수 있습니다.
print(df["name"].head(10)) # 특정 컬럼만 보기
#특정 컬럼만 보기
columns = ["name","city_id","state_id"]
df[columns].head(10)
References
[1] 2022.06.08 - [개발이야기/Python] - [Python] 파이썬#4 csv 파일 로드 #1 DicReader
'개발이야기 > Python' 카테고리의 다른 글
| [Python] 파이썬#7 - Pandas를 이용한 data frame의 sum, mean, nunique, counts, 함수적용 (0) | 2022.06.14 |
|---|---|
| [Python] 파이썬#6 - Pandas를 이용한 data frame의 indexing, join, query, filtering (0) | 2022.06.13 |
| [Python] 파이썬#4 - DicReader를 이용한 csv 파일 로드 (0) | 2022.06.08 |
| [Python] 파이썬 #3, File I/O, Networ I/O, pickle (0) | 2020.01.21 |
| [Python] 파이썬 #2 - Collections, 리스트, 셋, 튜플, 딕션어리 (0) | 2020.01.21 |
