
이전까지는 데이터를 로드하여 data frame으로 만들고 read, filtering 하는 방법에 대해서 포스팅 했습니다. data frame은 DB의 table 개념과 유사하여 sql에서 지원하는 것들에 대한 기능을 하는 함수들을 제공했었습니다.
이번 포스팅에는 sql의 group함수들을 data frame에서 어떻게 이용할 수 있는지를 확인해 보겠습니다.
이글은 Phtyon 3를 기반으로 작성되었습니다.
데이터 로드
기본예제로 사용할 sample 예제를 로드해 보겠습니다.
import pandas as pd
xls = pd.ExcelFile('yelp.xlsx')
df = xls.parse('yelp_data')
df.head()
Computation
# count(), sum(), mean() - 총 개수, 합계, 평균
간단하게 합계와 평균 함수를 테스트해 봅니다. 먼저 포장 가능한 식당의 개수가 몇개인지 세보고, 이 식당들의 별점 평균을 구해 보겠습니다.
take_out_ok = df['take_out'] == True
print('포장 가능 식당:', df[take_out_ok]['review_count'].count())
print('포장 가능 식당에 대한 review 개수:',df[take_out_ok]['review_count'].sum())
print('포장 가능 식당에 대한 평점 평균:',df[take_out_ok]['stars'].mean())
# value_counts() - group별 개수
만약 특정 컬럼을 sql의 group by 묶고 그 개수를 couting 하고 싶다면 value_counts()를 사용할 수 있습니다.
#group by
print(df["city"].value_counts())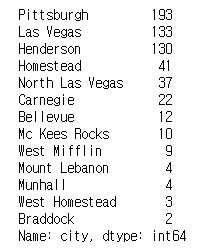
# nunique() - unique한 count
만약 null이 아닌 unique한 값의 개수만 세고 싶다면 아래와 같이 nunique() 함수를 이용합니다.
#null이 아닌 unique 계산
print(df['category_0'].nunique())
Column의 생성과 변경
위 테이블은 category_0과 category_1로 세분화 하여 나눠져 있습니다. 만약 이 두가지 정보를 다 가지고 있는 새로운 커럼을 만들고 싶다면 아래와 같이 간단하게 새로 추가될 컬럼명에 신규 값을 넣으면 됩니다.
df['categories'] = df['category_0'].str.cat(df['category_1'], sep=',')
df.head()
dataframe에 'categories'가 새로 추가된걸 알수 있습니다. 굉장히 쉽죠?
위에서는 str.cat을 가지고 두개의 문자열을 합쳤습니다. 만약 복잡한 작업을 해야하는 경우 해당 작업을 특정 함수로 만들고 이 함수를 이용하도록 할 수 있습니다.
# 함수의 적용
def star_to_rating(x):
return x * 2
df['rating'] = df['stars'].apply(star_to_rating)
df.head()대단히 복잡한 식은 아니지만 5점 만점짜리 평점을 10점 만점짜리로 환산하는 star_to_rating()이라는 함수를 만들었습니다.
이 함수를 적용하기 위해서는 apply()를 이용하면 됩니다. 물론 이렇게 짧은 함수라면 lambda로 만들어도 되겠죠?

'개발이야기 > Python' 카테고리의 다른 글
| [Tensorflow] Mac에서 tensorflow 설정 (0) | 2025.01.26 |
|---|---|
| [Python] 파이썬#8 - Pandas의 groupby, numpy, pivot table의 사용 (0) | 2022.06.16 |
| [Python] 파이썬#6 - Pandas를 이용한 data frame의 indexing, join, query, filtering (0) | 2022.06.13 |
| [Python] 파이썬#5 - Pandas를 이용한 Excel 파일 Load (0) | 2022.06.11 |
| [Python] 파이썬#4 - DicReader를 이용한 csv 파일 로드 (0) | 2022.06.08 |
