
Pandas로 만들어진 data frame을 grouping하는 다양한 방법에 대해서 얘기합니다. 또한 numpy library와 pivot table을 이용하여 데이터를 묶어서 의미있는 값을 가지는 집합으로 나타내 보겠습니다.
이글은 Phtyon 3를 기반으로 작성되었습니다.
데이터 로드
기본예제로 사용할 sample 예제를 로드해 보겠습니다. 앞서 여러번 했으므로 이번에는 한번에 하겠습니다.
import pandas as pd
# 엑셀파일 로드
xls = pd.ExcelFile('yelp.xlsx')
# 각 sheet의 데이터 로드
df = xls.parse('yelp_data')
df_cities = xls.parse('cities')
df_states = xls.parse('states')
# yelp_data와 city sheet를 id를 이용하여 조인
df = pd.merge(left=df, right=df_cities, how='inner', left_on='city_id', right_on='id')
# 조인된 yelp_data와 state sheet를 id를 이용하여 조인
df = pd.merge(left=df, right=df_states, how='inner', left_on='state_id', right_on='id')
# 중복된 컬럼 제거
del df['id_x']
del df['id_y']
df.head()
자 데이터는 다 만들었습니다. 이제 grouping하는 기법들에 대해서 진행해 봅니다.
groupby
먼저 데이터를 citiy별로 grouping 해 보겠습니다.
df.groupby(['city']).groups.keys()
city의 정보만 dic_keys type으로 출력됩니다. groupby()를 통해 city column을 기준으로 묶었기 때문입니다.
df.groupby(['city']).groups['Las Vegas']도시중에 Las Vegas만 뽑아 보겠습니다. 이렇게 뽑으면 index값이 출력됩니다.

len() 함수를 쓰지 않아도 친절하게 133개라는것 까지 마지막에 찍어주네요~
사실 이렇게 뽑지 않아도 아래와 같이 unique()를 사용할 경우 array 형태로 도시들을 뽑아 낼 수 있습니다.
df['city'].unique()
groupby()의 함수는 있지만 사실 도시에 따른 각종 정보를 보고 싶은것이지 단순히 도시명의 distinct를 보고싶은 경우는 적습니다. 따라서 numpy를 이용하여 좀더 유의미한 정보를 출력해 볼수 있습니다.
numpy
numpy library는 수치계산을 하기 위한 함수들을 제공합니다. 흔하게 사용하는 합계, 평균등이죠. numpy를 사용하기 위해서는 library import부터 수행해야 합니다.
import numpy as np
df.groupby(['city']).agg([np.sum, np.mean, np.std])["stars"]도시별로 groupby로 묶은 뒤에 np에서 제공하는 함수들을 이용하기 위해 agg()라는 함수를 사용합니다. 즉 위 함수는 아래와 같은 의미를 갖습니다.
- city로 grouping 하겠음.
- 보고싶은건 별점(stars) 컬럼에 대한 합계, 평균, 표준편차임

이제 좀 유의미한 정보가 나온것 같습니다. 합계를 보면 평점 정보가 많은 도시들이 어디인지를 파악할 수 있고, 별점의 수준은 어떠하며, 식당간 얼마나 별점간 차이가 벌어졌는지를 대략적으로 볼 수 있습니다.
pivot table
pivot table은 groupping을 좀더 고급스럽게? (rich하게?) 만들어줄수 있습니다. 여기서는 pivot table을 가지고 2차, 3차 groupping까지 해보겠습니다.
pivot_city = pd.pivot_table(df, index=['city'])
pivot_city # type은 data frame 임.pandas의 pivot_table() 함수로 간단하게 pivot table을 생성할 수 있습니다. 여기서 index에는 grouping한 컬럼명 (기준이 될 컬럼명)을 넣습니다.
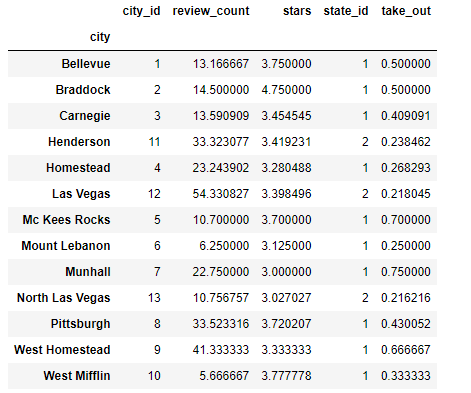
"어떤 컬럼을 뽑아달라, 어떻게 보여달라"를 지정하지는 않았지만 일단 위와같은 값이 나옵니다.
- 도시명으로 grouping되었다.
- 숫자를 갖는 컬럼들이 출력되었다.
- 값은 도시별 평균값이다.
즉 grouping할 컬럼만 지정하면 알아서 숫자로된 나머지 컬럼들의 평균값을 구해서 보여줍니다.
# 여러개의 index를 사용 - 자동으로 sorting 해줌. (groupby의 기준을 여러개로 할때)
pivot_state_take = pd.pivot_table(df, index = ["state", "take_out"])
pivot_state_take이번에 index에 두개의 column값을 넣었습니다. 예상했던 것처럼 DB에서 groupby()를 1차, 2차로 한것과 동일합니다.
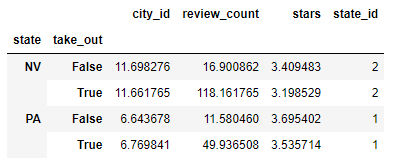
state를 1차로 grouping하고 2차 grouping으로 포장여부를 묶었습니다.
DB에서 sql을 만들때 group by만 하지는 않습니다. where절에 조건문도 대부분 들어갑니다. 이를 만들어 보기위해 이전에 나왔던 boolean indexing을 써봅니다.[1]
bars_rest = df['category_0'].isin(["Bars", "Restaurants"])
df_bars_rest = df[bars_rest]
df_bars_rest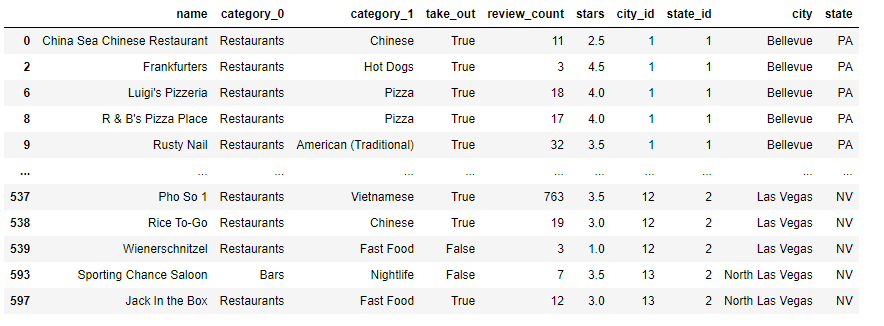
"category_0" 컬럼에서 Restaurants와 Bars만 뽑았습니다. 이 상태로 다시 grouping을 진행합니다.
pivot_state_cat = pd.pivot_table(df_bars_rest, index = ["state", "city", "category_0"])
pivot_state_cat[["review_count", "stars"]]state, city, category_0으로 3차 grouping을 진행한 후에 review 개수와 별점 정보만 뽑습니다.

aggfunc을 이용한 numpy 함수 적용
pivot_table은 grouping을 위한 table로 group index가 아닌 다른 column들은 어떤 그룹함수로 묶여야 합니다. 기본값은 mean으로 위와같은 값들이 출력됩니다. 하지만 review_count의 경우 평균보다는 합계의 정보가 필요합니다.
기본 그룹함수의 형태를 바꾸려면 aggfunc을 이용합니다.
pivot_agg = pd.pivot_table(df,
index=["state","city"],
values=["review_count"], # aggfunc()을 사용할 특정 컬럼 지정
aggfunc=[np.sum] # 해당 컬럼에 적용할 function
)
pivot_agg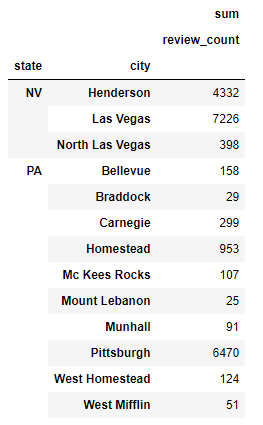
원하는대로 pivot_table을 사용했으나 mean이 아닌 sum으로 처리된 결과를 출력했습니다.
pivot_agg2 = pd.pivot_table(df,
index=["state","city"],
values=["review_count"], # aggfunc()을 사용할 특정 컬럼 지정
columns=["take_out"], # 결과에 대한 추가 분리가 필요한 컬럼 지정
aggfunc=[np.sum] # 해당 컬럼에 적용할 function
)
pivot_agg2이번엔 좀더 세분화한 테이블을 작성합니다. "state", "city" 두개의 값으로 1,2차 grouping을 한 뒤에 np.sum을 사용할 컬럼을 values param으로 선택합니다. 그리고 결과에 따라 추가 분리를 하고 싶은 컬럼인 "take_out"을 추가합니다.

마지막으로 review_count는 sum으로, stars는 mean으로 지정하여 한번에 뽑아 보겠습니다.
pivot_agg3 = pd.pivot_table(df,
index=["state","city"],
columns=["take_out"], # 결과에 대한 추가 분리가 필요한 컬럼 지정
aggfunc={"review_count":np.sum, "stars":np.mean} # 컬럼별로 사용할 np 함수 지정
)
pivot_agg3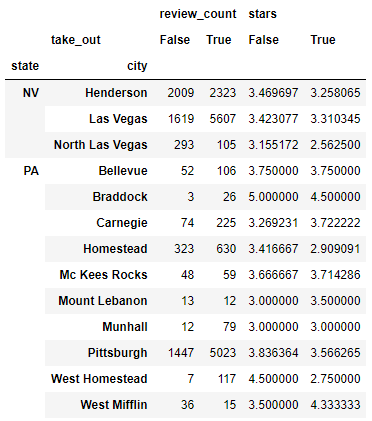
pandas를 이용한 자료 출력 및 가공에 대한 포스팅은 이로서 마칩니다.
파이썬을 볼때마다 느끼는거지만.."참 형식이 없다..(정형화 되어있지 않다.)" 입니다. 프로그래밍을 모르는 입문자에게는 익히기 편하다는 좋을뜻일수도 있고, 좀더 high level의 언어를 다루는 개발자들에게는 그 반대의 의미가 될수도 있습니다.
편하면서 불편한 언어랄까...제 느낌은 그렇습니다.ㅎㅎ
Referneces
'개발이야기 > Python' 카테고리의 다른 글
| [Tensorflow] Mac에서 tensorflow 설정 (0) | 2025.01.26 |
|---|---|
| [Python] 파이썬#7 - Pandas를 이용한 data frame의 sum, mean, nunique, counts, 함수적용 (0) | 2022.06.14 |
| [Python] 파이썬#6 - Pandas를 이용한 data frame의 indexing, join, query, filtering (0) | 2022.06.13 |
| [Python] 파이썬#5 - Pandas를 이용한 Excel 파일 Load (0) | 2022.06.11 |
| [Python] 파이썬#4 - DicReader를 이용한 csv 파일 로드 (0) | 2022.06.08 |
